前言
今天凌晨2点,OpenAI的12天直播,终于迎来了大结局! 奥特曼,也在一片圣诞的气息中终于回归。为大家带来了最后的压轴大戏。
OpenAI o3。
又一次超群,又一次把模型的能力,推到了新的高度。也向全世界证明了,OpenAI,依然在铁王座上牢不可摧。
我也想起了OpenAI研究员在发布o1之前的那句话:
“我们通往AGI的路上,已经没有任何阻碍了”
之所以OpenAI直接发布o3没有o2,原因也挺简单的。因为跟英国电信服务提供商O2可能存在版权或商标冲突,所以直接跳过了。直接到o3了。而OpenAI直播一完,X上基本就沸腾了。
o3的能力,对现在所有模型,几乎都直接是降维打击。
看下o3的能力吧。一些粗的评测集简单过一下。
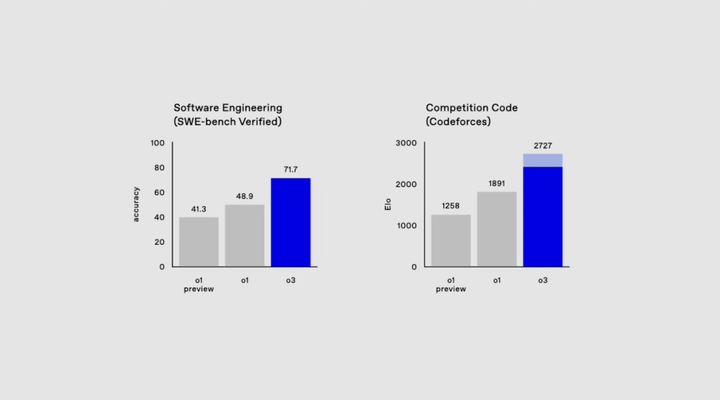
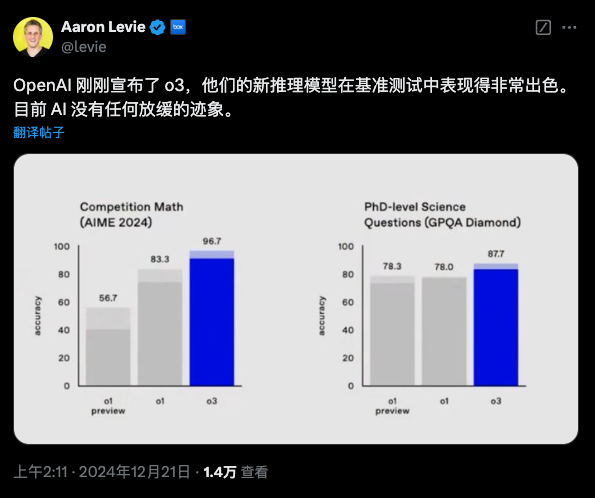
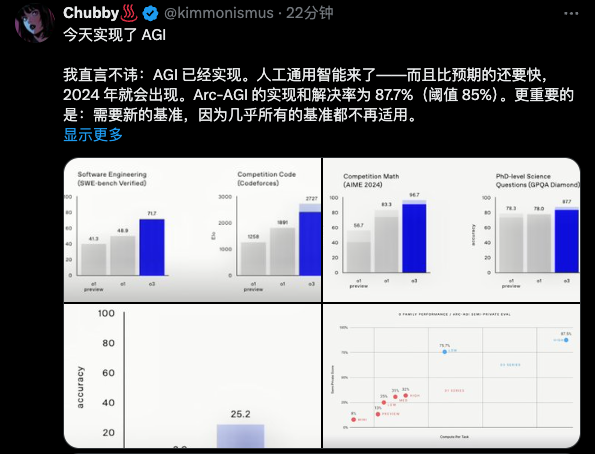
左边的是软件工程考试(SWE-Bench Verified),这就像是一个考写程序的考试,比如你写一个软件要它快速、准确,还不能有 bug(小错误)。这是考察 o3 是否能像一流的软件工程师一样写出完美的代码。
o3 的成绩:71.7%,比o1还强了不少。
大家需要升级或者订阅ChatGPT的童鞋可以参考本文:升级订阅教程
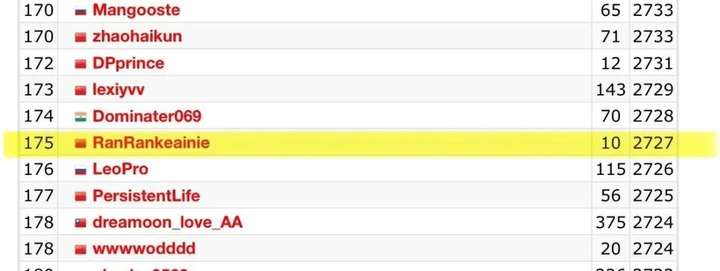
右边的那个基准比较猛,Codeforces,一个全球著名的编码竞赛平台。
o3的得分是2727,这个得分,相当于整个榜单的第175名,已经超越了99.99%的人类了。
o1的代码能力已经强到爆炸了,而o3,又向AGI的山顶,前进了一大步。
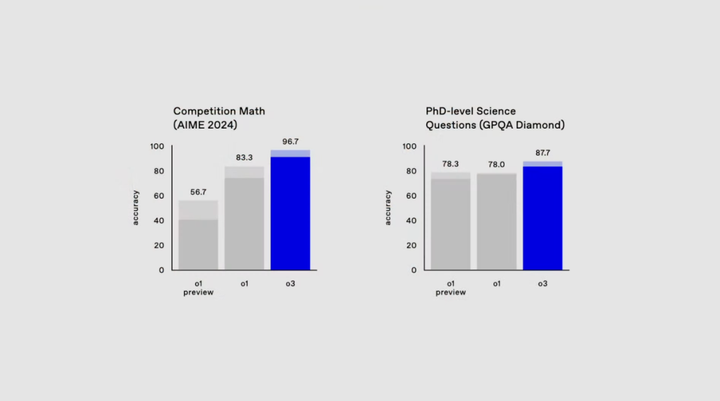
数学竞赛AIEM 2024和博士级科学考试GPQA Diamond。AIEM 2024接近满分,如果我没记错的话,这应该也是第一次AI能达到有AIEM接近满分的水平。博士级科学考试有进化,但没数学和编程进化的这么猛!接下来的这个数学基准比较有趣一点。
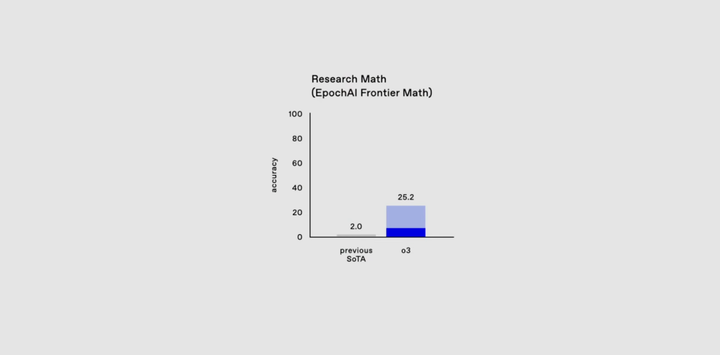
FrontierMath,Epoch AI 开发的一个数学基准测试,由60多位顶尖数学家的合作开发,旨在评估人工智能在高级数学推理方面的能力。
为了避免数据污染,所有的题目都是原创的且从来没有发布过的新题目。
之前GPT-4 和 Gemini 1.5 Pro这种模型去评估的时候,成功功率不足2%,与其他传统数学基准(如 GSM-8K 和 MATH)中超过90%的成功率形成鲜明对比。
而这一次,o3直接达到了25.2。
当各大其他模型都还在卷传统数学基准的时候,o3真的已经进入了另一个世界了。。。 对于其它大模型而言这就不在一个层级!!!
然后,就是我觉得,整个基准里,最有趣的一个基准了:ARC-AGI
先说说这是个啥玩意。
ARC-AGI于2019年首次提出,旨在通过一系列抽象和推理任务来测试AI系统的能力。主要是因为传统的技能测量方法并不能有效代表智能,因为它们往往依赖于先前知识和经验,而真正的智能应体现在广泛的适应能力和通用性上。所以,ARC-AGI诞生了,里面的这些任务要求AI识别模式并解决新问题,每个任务由输入输出示例组成。这些任务以网格形式呈现,每个方块可以是十种颜色中的一种,网格的大小可以从1x1到30x30不等。参与者需要根据给定的输入生成正确的输出,测试其推理和抽象能力。可以简单的理解成,找规律。
大概就是这样的。

非常的难且抽象。
过去几代模型的评分在此: GPT-2 (2019): 0%
GPT-3 (2020): 0%
GPT-4 (2023): 2%
GPT-4o (2024): 5%
o1-preview (2024): 21%
o1 (2024): 32%
o1 Pro (2024): ~50%
但是今天,o3的分数,达到了恐怖的87.5%。相关的数据汇总如下图所示>
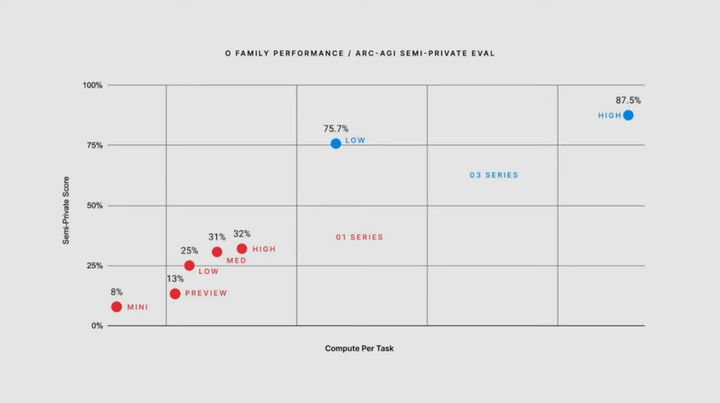
从0%到5%,整整花了5年的时间,而如今,从5%到87.5%,仅仅只花了半年。而对应的,人类的阈值分数,是85%。我们通往AGI的路上,已经没有任何阻碍了。
不过o3强归强,但是又是一个期货(套路满满),OpenAI目前只对红队开放,如果是巨佬的话,可以去申请试试。

网址在此:https://openai.com/index/early-access-for-safety-testing/
目前不知道o3什么时候放出,但是OpenAI又基于o3,训了3个小尺寸的o3模型。
目前o3-mimi,预估在1月底可以对外开放,但是感觉到时候,肯定又是pro会员专属的模型了。
我越来越期待,2025年AI行业的进化了。推理模型、Agent、AI硬件、世界模型。每一个都是比这个中间态的2024,都更让人兴奋的东西。2025,必是AI行业,真正的星辰大海。
End:大模型愈来愈强大,又一次改革在路上了,做到不掉队就是我能做的,冬至快乐哦~
小提示:
PS:如果你需要开通自己的ChatGPT Plus、Claude Pro的个人独享账号可以参考教程:使用支付方式订阅开通ChatGPT Plus、Claude Pro教程
欢迎加微信

公众号也可以哦
